从Base16到Base85, 谈谈Binary-to-text编码
起因
最近在看ImGui的代码,其中有个将字体数据嵌入到源码的写法1引起了我的注意,它采用了一种之前没接触过的编码方式:Base85。从这里开始,对相关的领域进行了一次简单的梳理。
什么是Binary-to-text编码2?
顾名思义,Binary-to-text编码是一种将二进制数据转换为文本形式的编码方式。更精确的说,它是一种将二进制数据转换为由 “可打印字符” 组成的文本流形式的编码方式。
为什么要存在这个东西?主要是为了解决如下两类问题:
- 某些传输信道或介质不支持二进制数据,例如E-Mail或NNTP;
- 某些传输信道或介质不能正确的处理8-bit字符编码(或者说:not 8-bit clean);
看下这个编码的两端,一边是二进制数据,一边是文本。
二进制数据,大家通常的理解是一个字节流,同时每1个字节由8个比特组成。稍微延伸一下,Quora上这个问题比较详细的解释了Why is one byte formed by 8 bits?
文本,在这个上下文中,特指的是ASCII编码中的printable characters。ASCII编码是一个7-bit的编码,最多可表示128个唯一字符。其中控制字符33个(0x0-0x1F, 0x7F),可打印字符95个(0x20-0x7E)。
一个重要的问题是,在现代二进制计算机中,文本(或字符)在实现上也是基于字节来存储,也就是虽然单个ASCII字符只需要用7-bit来描述,在具体实现中1个ASCII字符会被存储为1个字节,也即占用8-bit。换句话说,从信息编码效率来看,以字节形式存储的文本,编码效率最高不会超过87.5% (7/8),并随着编码中所实际使用的唯一字符数的降低而进一步降低。与之对应的,Binary-to-text编码的效率通常也会低于1,也就是编码后的文本串所占用的字节数通常要大于原始二进制数据所占的字节数。
回到ImGui将字体嵌入源码的情况:字体文件是二进制数据,而C++源码中的string literal当然无法支持二进制数据,因此这里使用了Base85将二进制数据编码为文本流,再嵌入到源码中。
Base16
Base16或者说是hexadecimal,应该是程序员们最熟悉的一种Binary-to-text编码了。其文本中的单个字符具有16种唯一值,能表示4-bit的信息(2^4 = 16),因此一个8-bit的字节刚好可以用两个字符来表示,编码效率为50%。
对应到文本字符的选择上,理论上可以从可打印字符中任意挑选16个来表示,Base16实际选择了最容易理解的0, 1, 2, …, 9, a, b, c, d, e, f这16个字符来分别表示0 ~ 15,其中这6个字母大小写不敏感。
看个例子,开发人员常用的HexViewer类工具,是一种典型的Base16转换场景。例如用HexViewer打开一个.zip文件,可以看到其前4个字节的Magic word为:“PK␃␄”:

Base64
Base64应该是使用最多的Binary-to-text编码,被广泛用于互联网环境,例如在HTML/CSS中嵌入二进制数据,在E-Mail消息中编码二进制附件文件等。其文本中的单个字符具有64种唯一值,能表示6-bit的信息(2^6 = 64),因此3个字节的二进制数据(3 x 8-bit)刚好可以用4个字符来表示(4 x 6-bit),编码效率为75%。
Why 64? 主要原因是:
- Base为2的n次幂时,方便进行Base 2到Base 2^n的转换(n个bit为一组进行转换即可);
- ASCII中共有95个可打印字符,而64是<=95的数中最大的2的n次幂数;
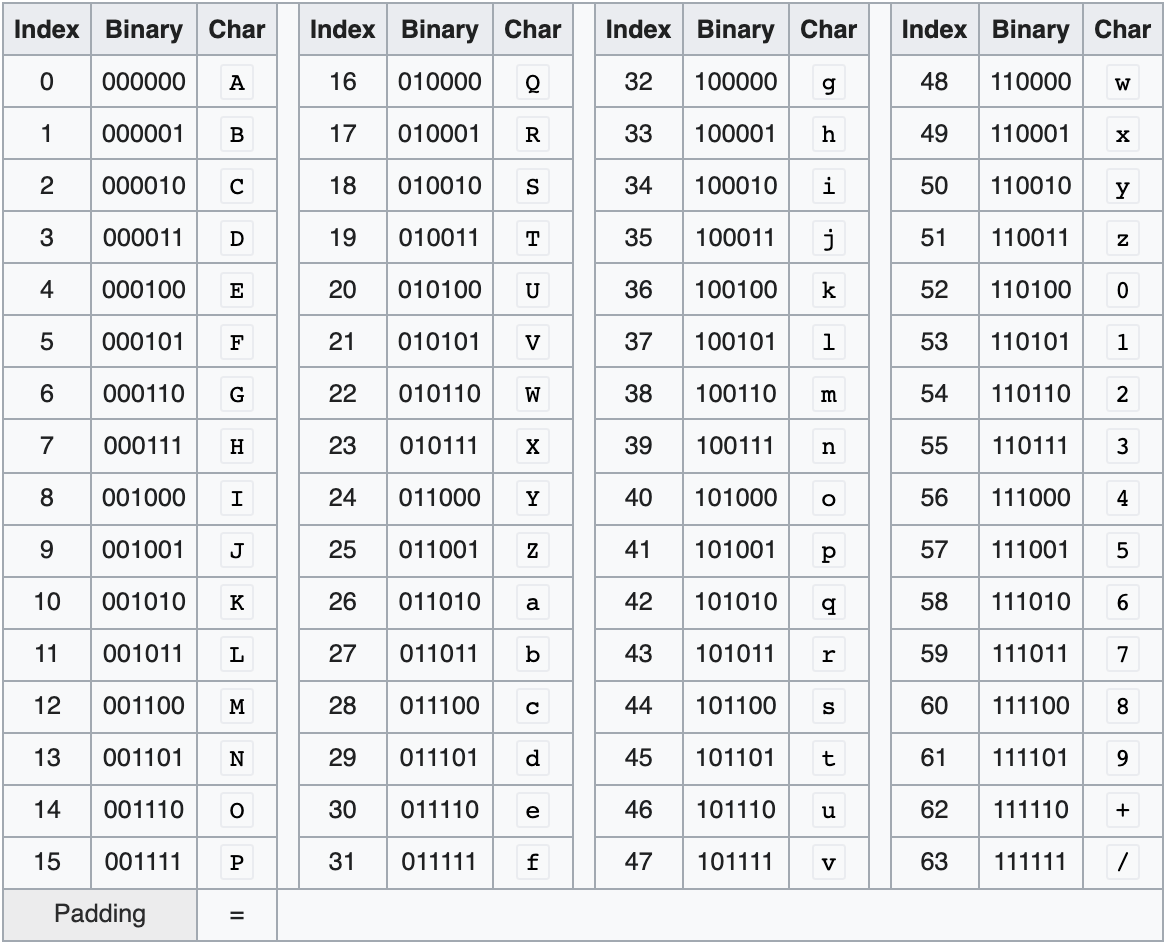
在文本字符子集的选择上,Base64稍有不同:大写字母A-Z表示0-25,小写字母a-z表示26-51,数字0-9表示52-61,+表示62,/表示63。此外,=字符用于将编码后文本长度padding到4的倍数。
网上有简易的Base64编码在线转换工具3,我们来看个例子:
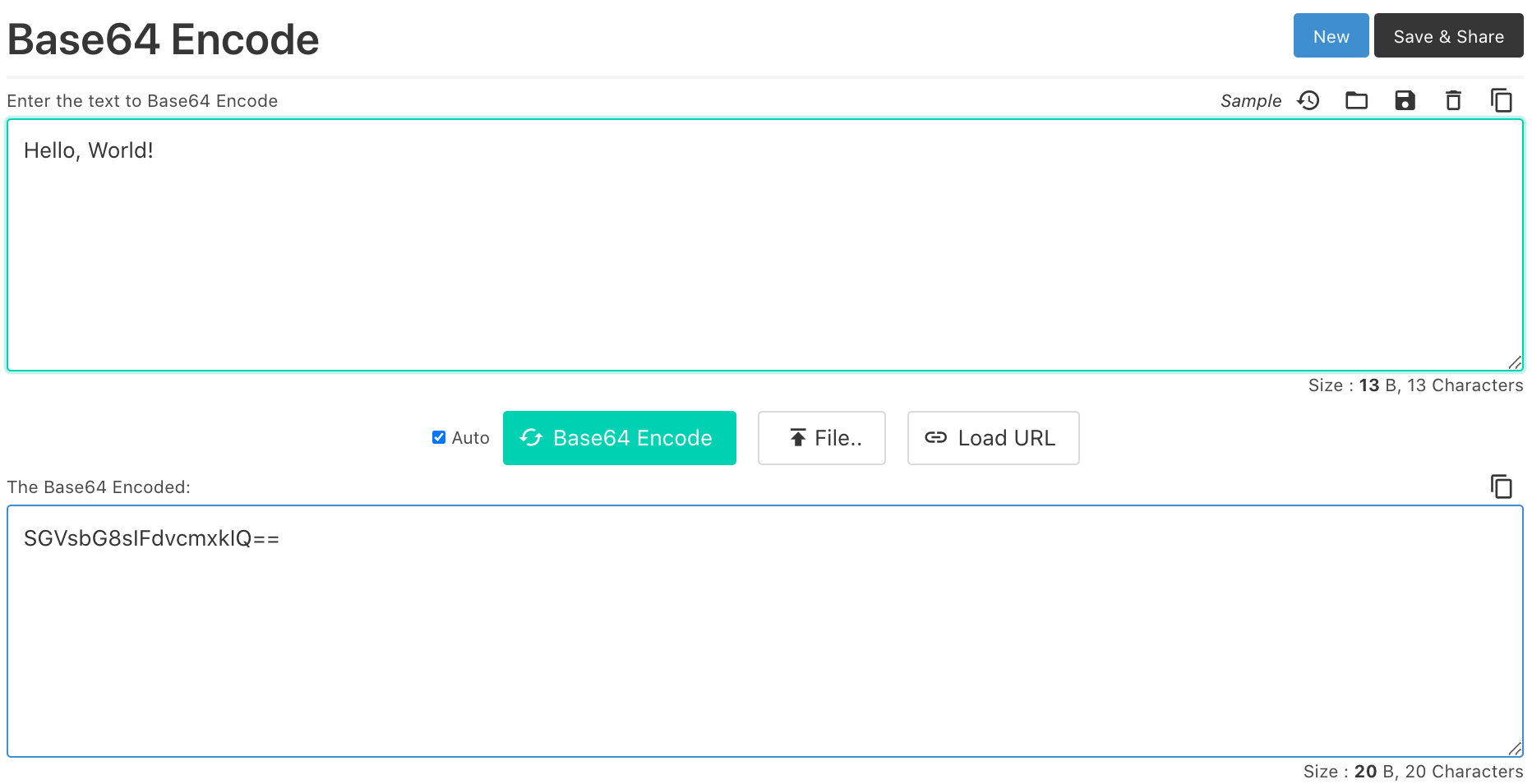 输入文本中的前3个字节为"Hel",对应的二进制为:01001000 01100101 01101100。
将之按6-bit为一组切分为4组,结果为:010010 000110 010101 101100,查表可知对应的Base64字符为:S G V s。
输入文本中的前3个字节为"Hel",对应的二进制为:01001000 01100101 01101100。
将之按6-bit为一组切分为4组,结果为:010010 000110 010101 101100,查表可知对应的Base64字符为:S G V s。
Base32
Base64整体而言能比较好的完成它的工作,但某些场景下,Base64所选择的文本字符子集,可能存在问题。
假如我们需要将一串纸质教科书上的Base64字符串重新输入到电脑中,需要考虑字符串的易读性,而Base64字符中存在不少容易混淆的情况:
- 大写字母I和数字1
- 小写字母l和数字1
- 小写字母o和数字0
此外,Base64混合了大写字母和小写字母,在键盘输入时会存在一定难度,如果要读出来也会比较麻烦。
基于此,Douglas Crockford设计了Base32,来解决这些问题。Base32的设计目标包括:
- Be human readable and machine readable.
- Be compact. Humans have difficulty in manipulating long strings of arbitrary symbols.
- Be error resistant. Entering the symbols must not require keyboarding gymnastics.
- Be pronounceable. Humans should be able to accurately transmit the symbols to other humans using a telephone.
综合 排除掉会影响易读性的字符 && 保持编码的相对紧凑性 这两个约束,选择了Base为32,字符集为10个数字和22个大写字母(去掉了I, L, O, U 这4个)。
Base32的每个字符能表示5-bit的信息(2^5 = 32),因此5个字节的二进制数据(5 x 8-bit)需要用8个字符来表示(8 x 5-bit),编码效率为62.5%。
与Base32思路类似的还有Base58,被用在Bitcoin的钱包地址4的格式上。不过由于58不是2的幂次方,在转换上会更麻烦一些。
Base85
Base32是在易读性上进行改进,另一个改进方向则是:提高编码效率。
Base64能用4个字符表示3个字节。现代主流计算机架构都是32-bit/64-bit,4字节长度的数据类型是使用最多的,那我们不妨想想,如何能更高效的编码4字节的二进制数据。
考虑到我们有95个可打印字符,而log95(2^32) = 4.87,也就是说如果95个字符全部用上,至少需要5个字符才能表示4个字节。对应的编码效率是32/40,也就是80%,高于Base64的75%。
那么在维持5个字符表示4个字节的效率框架下,我们继续找最小的base值,这样可以从95个字符中排除一些我们不想要的字符。
由于log85(2^32) = 4.993,同时log84(2^32) = 5.006,因此,85是能满足需求的最小base值。
由此得到Base85。在字符集的选择上,Base85选择了一个连续区段,从33("!")到117(“u”)。在编码时,先将4字节二进制数据视为一个32位的二进制整数,转换为5位的85进制数,再将每一位加上33得到5个对应的ASCII字符,即为Base85编码后结果。
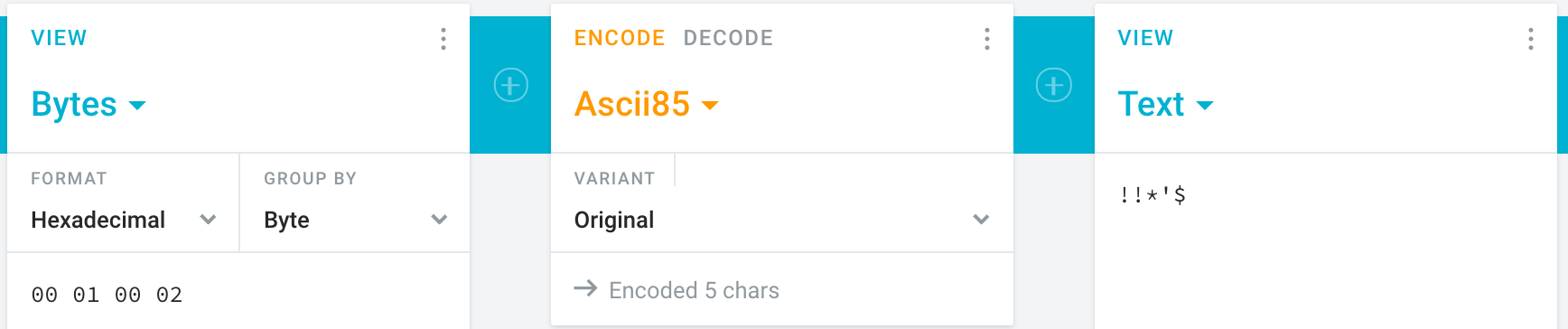
看个例子:假定一个4字节数0x00010002,对应到10进制是65538。我们将它转换为85进制数:
65538 / 85 = 771 ... 3
771 / 85 = 9 ... 6
因此结果5位85进制数为:0 0 9 6 3,我们验算一下:
9 x 85^2 + 6 x 85^1 + 3 x 85^0 = 65538
然后将这5个数字分别加上33,得到对应的ASCII字符:! ! * ’ $
用网上的在线转换工具5再验证一下:
Base85的主要应用领域是Adobe的PostScript和PDF,另外git也用它来编码patch文件。
最后
还有比Base85编码效率更高的Binary-to-text编码吗?如果将text限定在95个可打印字符内应该是没有,但若放开这个限制的话,yEnc可以达到~93%的编码效率,有兴趣的同学们可以看看。