上下文工程 (Context Engineering) 学习笔记
这份笔记整理自李宏毅老师关于 AI Agent 原理的课程(视频, PDF),旨在提炼 Context Engineering 的核心概念与实操方法。
1. 核心定义:它与 Prompt Engineering 有何不同?
- Prompt Engineering (提示词工程):
- 关注点:输入格式与“神奇咒语”(如何问)。
- 目的:让模型给出更好的单次回答。
- Context Engineering (上下文工程):
- 关注点:自动化管理(喂什么数据/信息)。
- 目的:在 AI Agent 的长期运作中,动态决定哪些信息该进入模型的 Context Window(上下文窗口),核心目标是避免塞爆 Context 。
2. 源起:为什么在 AI Agent 时代需要它?
AI Agent 的运作模式是 “观察 (Observation) → 思考 → 行动 (Action)” 的循环,这导致了以下挑战:
- 输入持续膨胀:Agent 在执行任务的过程中,会积累大量的对话历史、工具使用记录和网页内容,导致 Context 迅速变长。
- 模型“注意力”有限:
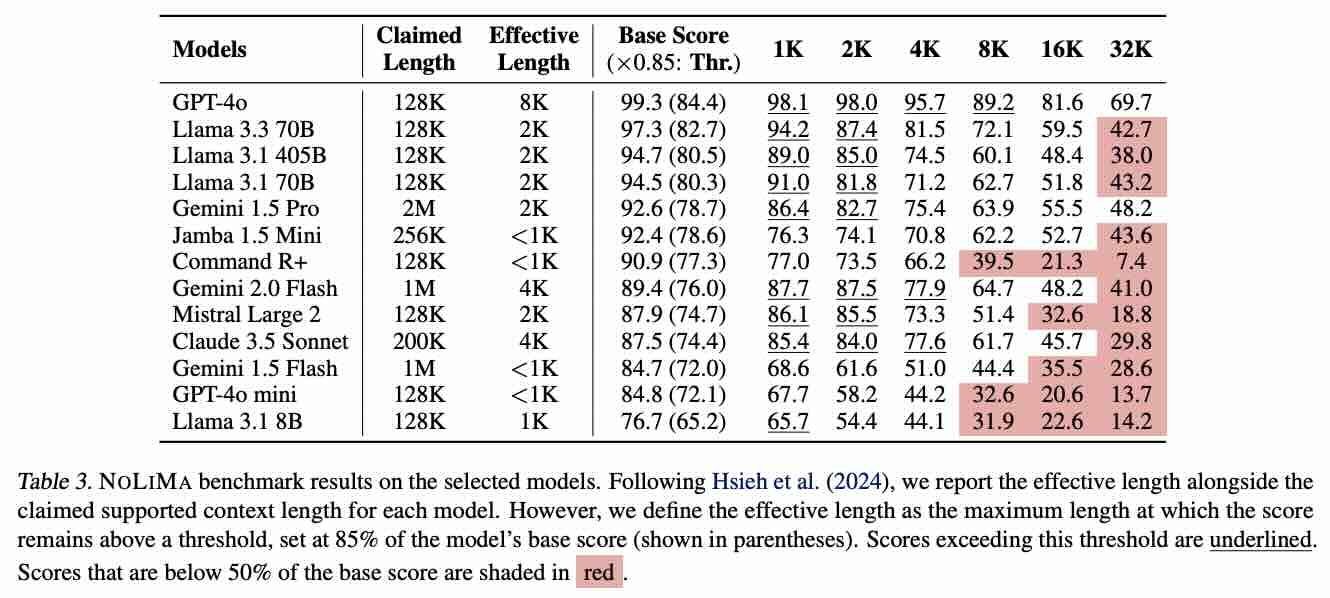
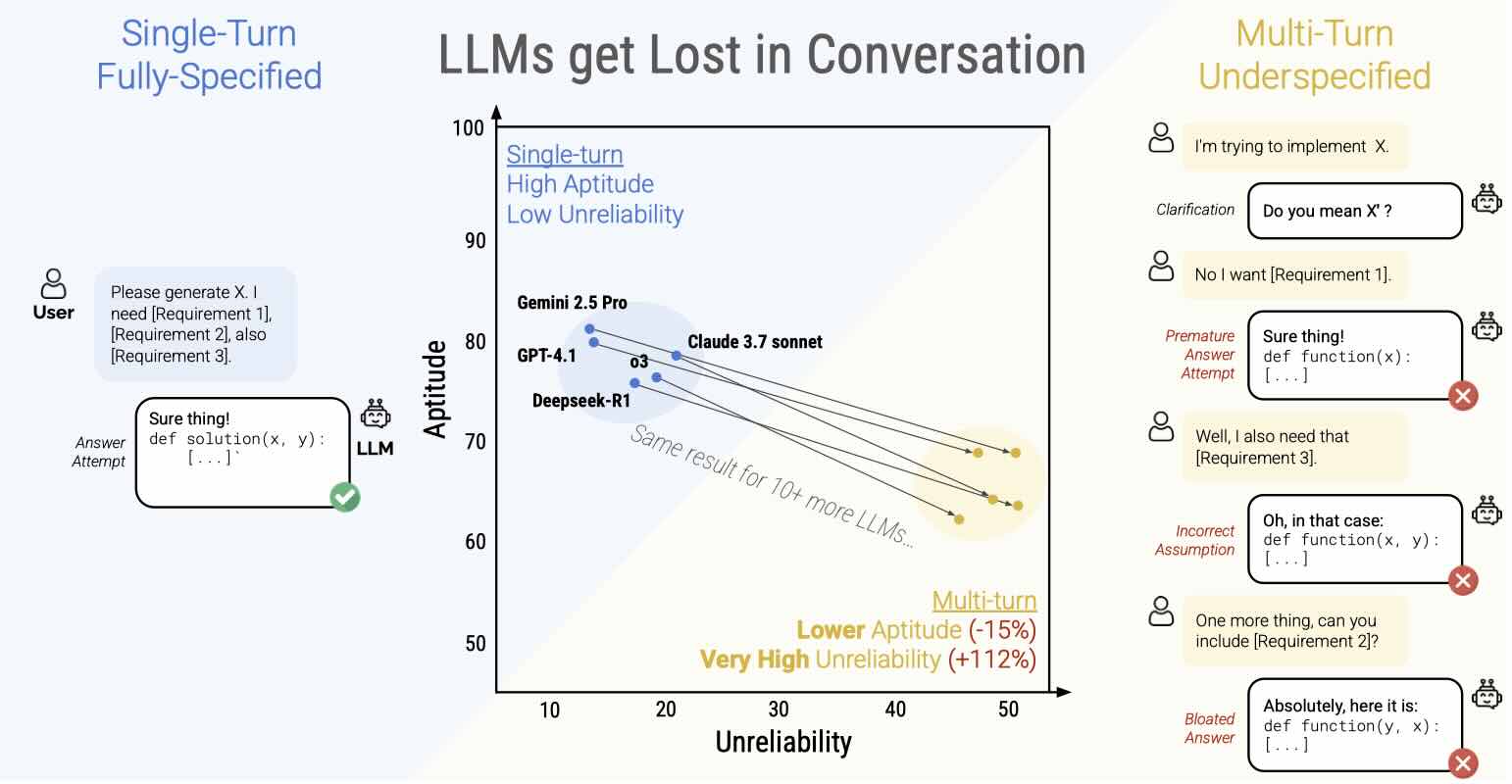
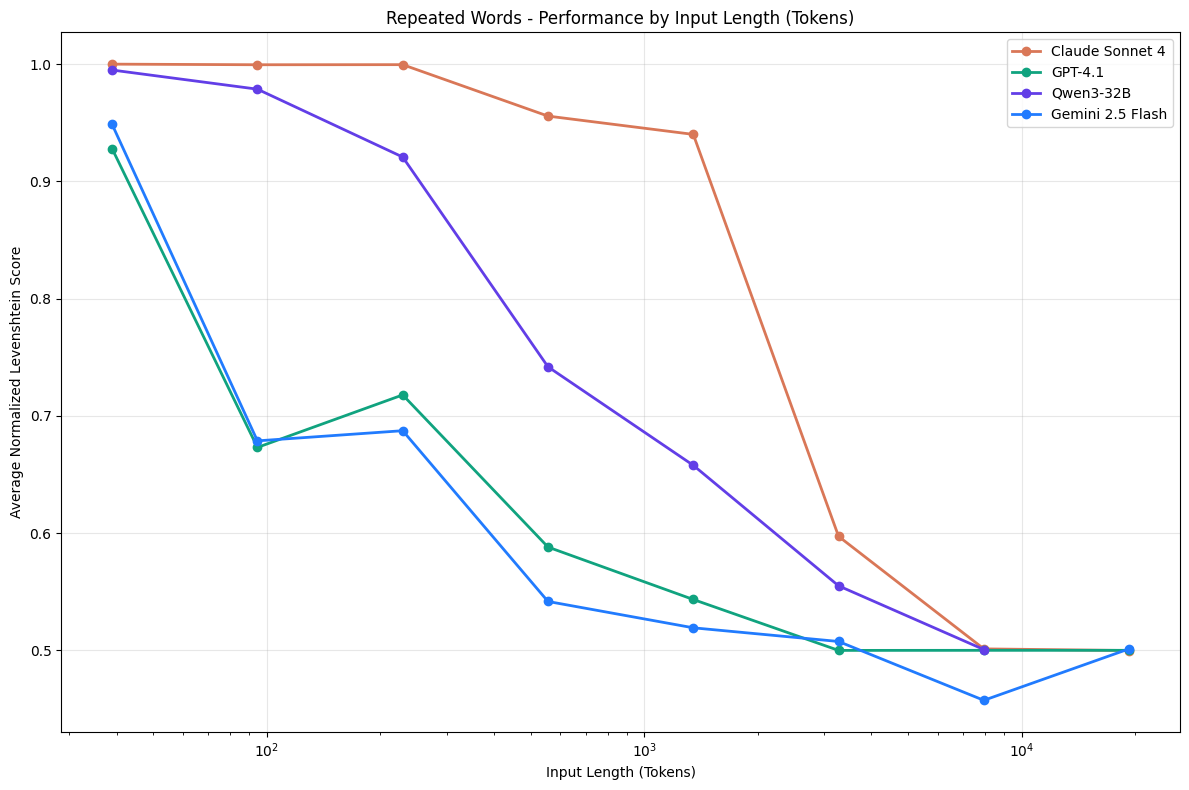
结论:为了让 Agent 能长期稳定运行,不能无脑塞入所有信息,必须进行“管理”。
3. 核心内涵:三大手段
Context Engineering 的最高指导原则是:“把需要的放进去,不需要的清出来”。具体实践分为三个维度:
A. 挑选 (Select / RAG)
不要把所有资料一次塞给模型,而是根据当下的 User Prompt 去检索最相关的信息。
- 数据 RAG:只抓取与当前问题相关的知识片段,利用检索(Retrieval)减少 Token 消耗。
- 工具 RAG:如果工具太多,不要把所有工具说明书都放进去,只检索当下可能用到的工具。
- 记忆 RAG:将过去的经历存入长期记忆库(如文件或数据库),需要时再“回忆”(检索)出来,而不是一直挂在 Context 里。
B. 压缩 (Compress / Summarization)
将冗长的过程转化为精简的摘要。
- 历程摘要:Agent 的中间思考过程或繁琐的工具操作(例如:网页点击了多次才订到位),在任务完成后,只需保留“订位成功”这个结果摘要。
- 定期归档:随着对话变长,将细节清除或存档,只保留摘要在 Context 中,防止无效信息占用空间。
C. 分工 (Multi-Agent)
透过多个 Agent 协作来隔离 Context,避免信息互相干扰。
- 隔离杂讯:例如“订餐厅”的 Agent 只需知道餐厅信息,“订旅馆”的 Agent 只需知道旅馆信息,互不干扰。
- 主控与分流:由一个 Leader 分派任务,各个 Sub-Agent 执行完后只回报最终结果。这样主 Context 就不会被各个子任务的繁杂过程给塞爆。
LangChain做了一个评测6:当任务领域为 1 时,single-agent 的性能是最好的,高于 multi-agent;任务领域达到 2 个或以上时,single-agent 的性能会显著下降,而 multi-agent 能保持稳定。这其实挺符合人类的真实情况:多人协作会受制于不充分的信息传递,但能获得术业有专攻、不受打扰的优势。
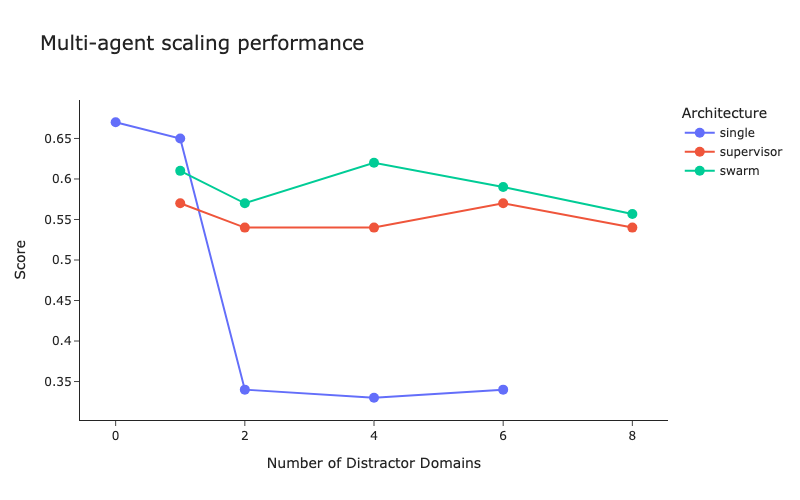
4. 总结
Context Engineering 就是 AI Agent 的信息注意力管理术,确保模型在处理复杂任务时,大脑(Context)里装的永远是最关键的信息。