VC2019 std::generate_canonical 性能问题
起因
最近一个项目中需要生成一堆均匀分布的伪随机浮点数。在C++11中,随机数生成算法以及相关的工具函数进行了不小的扩充。对于我的需求,常规的实现方法是:
#include <random>
#include <iostream>
int main()
{
std::random_device rd;
std::mt19937 gen(rd()); // Standard mersenne_twister_engine seeded with rd()
std::uniform_real_distribution<float> dis(1.0f, 2.0f);
for (int n = 0; n < 10; ++n) {
// Use dis to transform the random unsigned int generated by gen into a
// float in [1, 2). Each call to dis(gen) generates a new random float
std::cout << dis(gen) << ' ';
}
std::cout << '\n';
return 0;
}
其输出类似于:
1.80829 1.15391 1.18483 1.38969 1.36094 1.0648 1.97798 1.27984 1.68261 1.57326
哇,几行代码就可以实现一个高质量的均匀分布-伪随机-浮点数生成器,C++ NB !
然而,在进行性能测试时发现,MacOS版和Windows版存在巨大的性能差异(Windows下慢很多)。经过初步分析,运行耗时主要的差异点在uniform_real_distribution::operator()中,接下来细致分析一下。
uniform_real_distribution::operator()的具体实现
MacOS, XCode 12.0.1 (12A7300) :
template<class _RealType>
template<class _URNG>
inline
typename uniform_real_distribution<_RealType>::result_type
uniform_real_distribution<_RealType>::operator()(_URNG& __g, const param_type& __p)
{
return (__p.b() - __p.a())
* _VSTD::generate_canonical<_RealType, numeric_limits<_RealType>::digits>(__g)
+ __p.a();
}
Windows, VC2019 :
#define _NRAND(eng, resty) (_STD generate_canonical<resty, static_cast<size_t>(-1)>(eng))
template <class _Ty = double>
class uniform_real_distribution : public uniform_real<_Ty> {
};
template <class _Ty = double>
class uniform_real {
template <class _Engine>
_NODISCARD result_type operator()(_Engine& _Eng, const param_type& _Par0) const {
return _Eval(_Eng, _Par0);
}
template <class _Engine>
result_type _Eval(_Engine& _Eng, const param_type& _Par0) const {
return _NRAND(_Eng, _Ty) * (_Par0._Max - _Par0._Min) + _Par0._Min;
}
};
可以看到,逻辑很类似。其中__p.b()和__p.a()代表了此分布的上界和下界,对应实现就是返回一个运行期不变的_RealType值,因此可以认为主要耗时都在std::generate_cononical中。
测试程序
准备一个小测试程序:
#include <cstdio>
#include <random>
#include <chrono>
using namespace std::chrono;
int main()
{
const unsigned int N = 1000000000;
std::mt19937 gen;
double sum = 0;
auto start = system_clock::now();
for (unsigned int i = 0; i < N; i++) {
float v = std::generate_canonical<float, std::numeric_limits<float>::digits>(gen);
sum += v;
}
auto duration = duration_cast<microseconds>(system_clock::now() - start);
fprintf(stdout, "sum = %f\n", sum);
fprintf(stdout, "duration = %.2fms\n", duration.count()/1000.0);
return 0;
}
在我的MacBook Pro(16-inch, 2019)上测试,MacOS版本的输出:
sum = 499981300.522139
duration = 4203.75ms
同一台机器上,Windows版本(VC2019)的输出:
sum = 499981300.522139
duration = 34302.06ms
Windows版要慢8倍左右。
Profiling
使用Instruments的Time Profiler抓取数据,可以看到MacOS版本的测试程序多数CPU时间消耗在std::generate_canonical函数中:
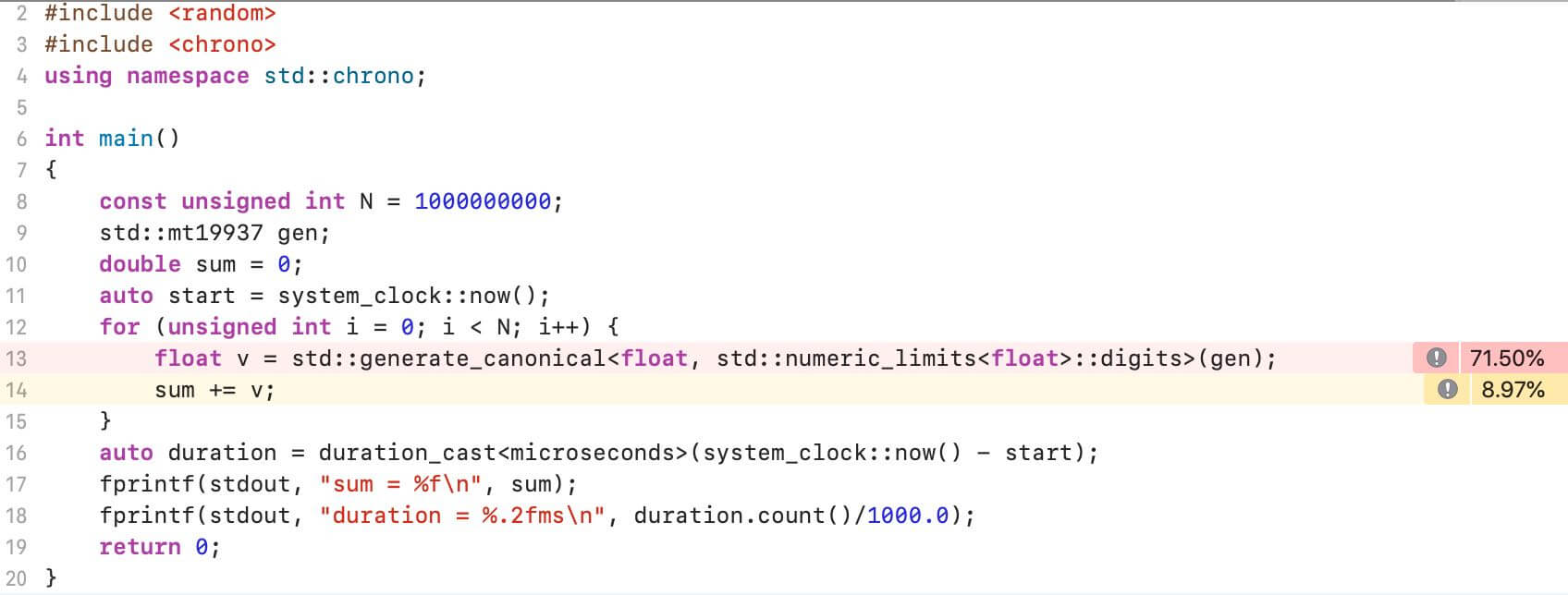
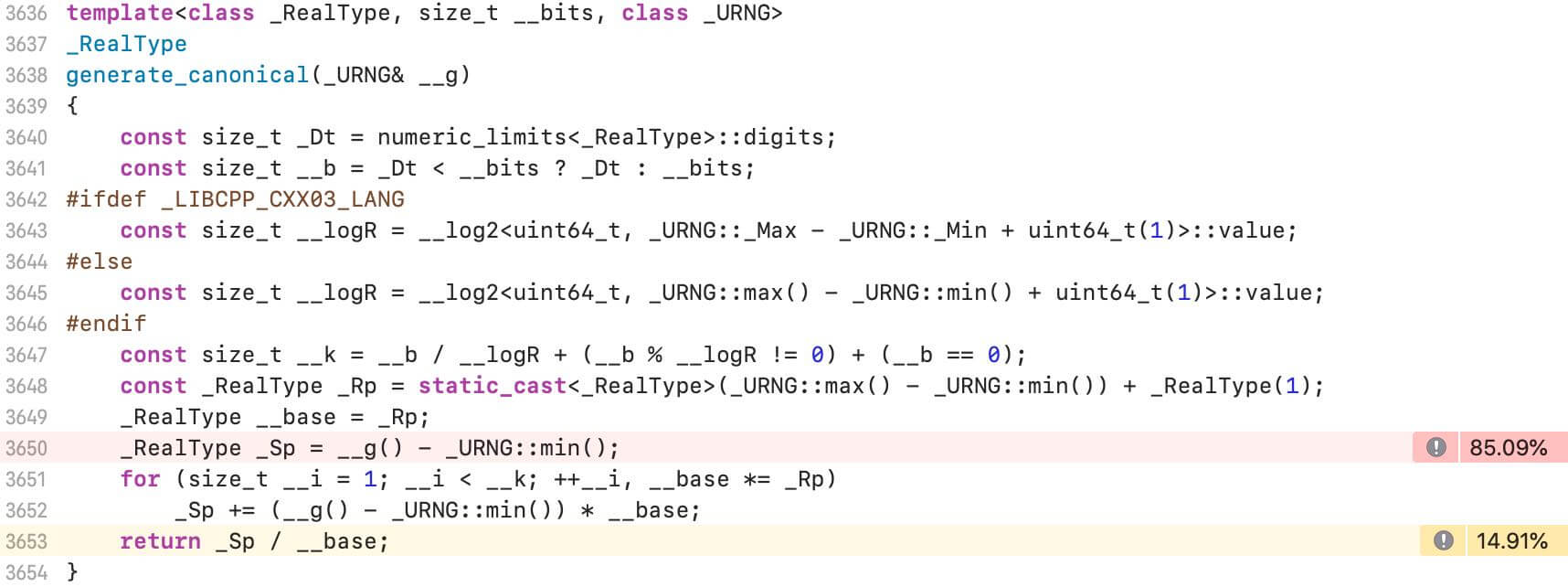
具体到std::generate_canonical内部,主要分布在调用伪随机数生成器以及数学运算代码上,看起来比较正常:
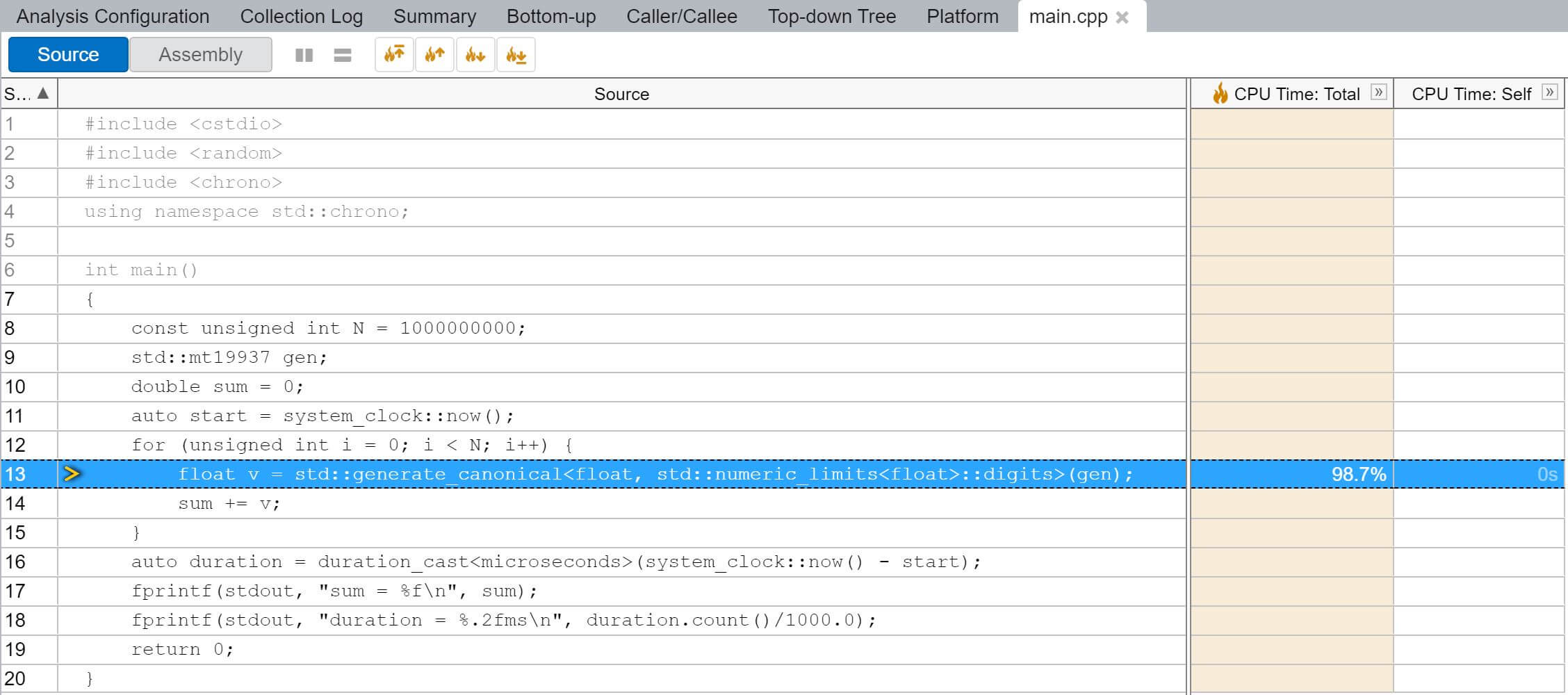
Windows上使用VTune抓取数据。可以看到绝大多数CPU时间都消耗在std::generate_canonical函数中,符合预期:
但进到std::generate_canonical内部就有点奇怪了,超过80%的时间用在求值一个变量_Ceil,猜测这就是导致Windows版本明显慢的原因:
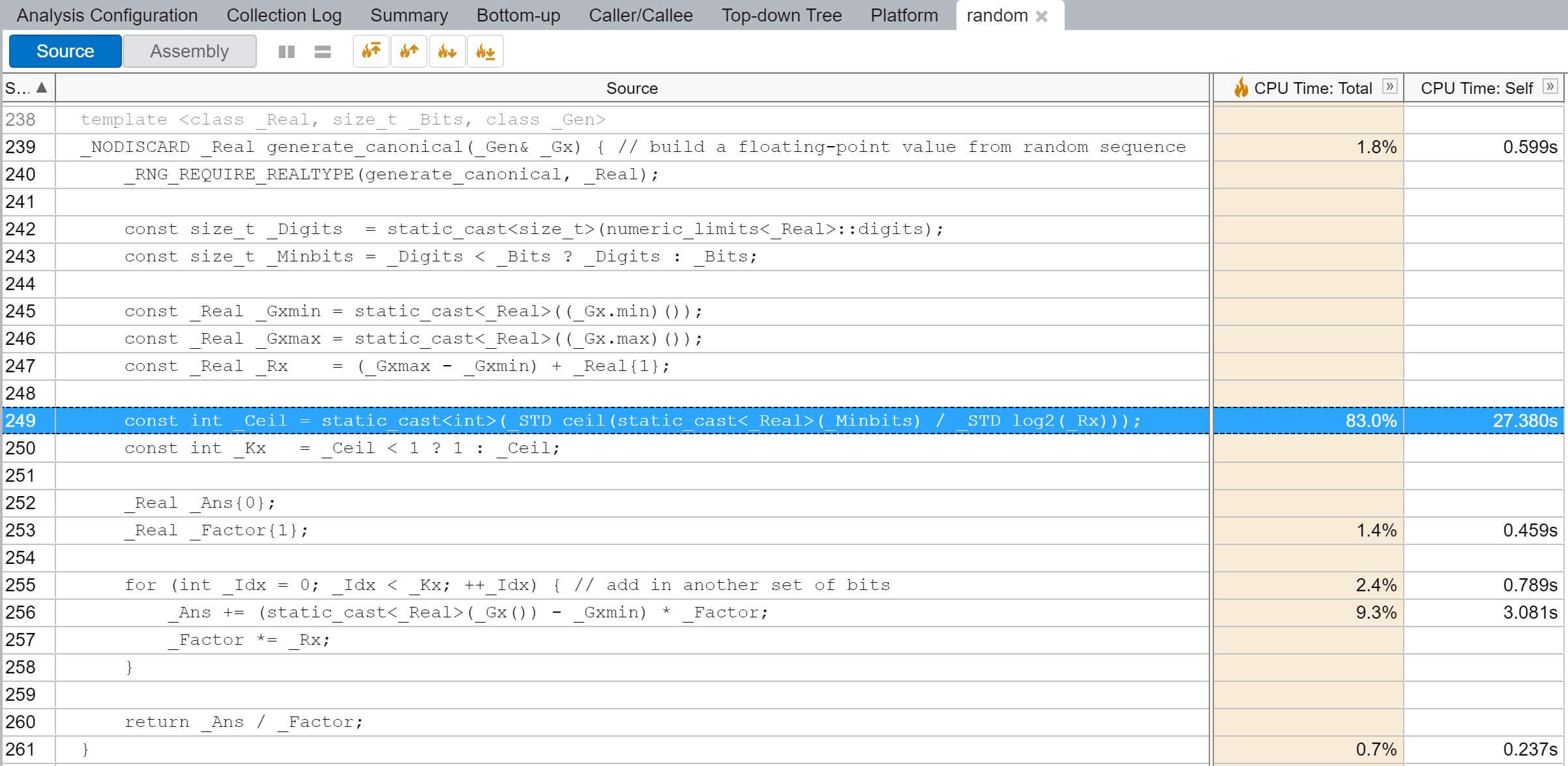
分析
对比Windows和MacOS下两份std::generate_canonical实现可知,Windows版中的_Ceil变量(不精确的)对应MacOS版中的__logR,都是用来确定后面的循环需要执行的次数。
Windows版中:
const int _Ceil = static_cast<int>(_STD ceil(static_cast<_Real>(_Minbits) / _STD log2(_Rx)));
const int _Kx = _Ceil < 1 ? 1 : _Ceil;
其中std::log2和std::ceil是标准库中的两个常规函数,因此会有两次function call的运行开销。
而在MacOS版中:
const size_t __logR = __log2<uint64_t, _URNG::max() - _URNG::min() + uint64_t(1)>::value;
const size_t __k = __b / __logR + (__b % __logR != 0) + (__b == 0);
在我们的测试程序中,此处的_URNG是std::mt19937,其max()为0xFFFFFFFF,min()为0,因此上面__log2模版的第二个参数为0x100000000。
继续看__log2模版类的实现:
template <unsigned long long _Xp, size_t _Rp>
struct __log2_imp
{
static const size_t value = _Xp & ((unsigned long long)(1) << _Rp) ? _Rp
: __log2_imp<_Xp, _Rp - 1>::value;
};
template <unsigned long long _Xp>
struct __log2_imp<_Xp, 0>
{
static const size_t value = 0;
};
template <size_t _Rp>
struct __log2_imp<0, _Rp>
{
static const size_t value = _Rp + 1;
};
template <class _UIntType, _UIntType _Xp>
struct __log2
{
static const size_t value = __log2_imp<_Xp,
sizeof(_UIntType) * __CHAR_BIT__ - 1>::value;
};
哇,还是蛮精巧的,通过模版元编程的方式在编译期计算出了_Xp(在我们的例子中为0x100000000)的log2值,当然这里假设了_Xp为2的N次幂且N<=_Rp。
结论
- MacOS下std::generate_canonical的实现采用了模版元编程的方式进行优化,通过编译期求值的方式,使得调用伪随机数生成器之外的其它额外开销非常小。
- 反观VC2019中的对应实现,使用了两个常规函数std::log2和std::ceil,带来了较大的额外开销,在密集调用的场景下性能很差。