一个测试CPU分支预测的示例程序
起因
最近在看一些CPU Microarchitecture相关的资料。其中的分支预测器1,虽然知道概念,但其对性能的影响程度没有清晰的概念。因此,设计了一个小测试程序2。
Test program
#include <cstdio>
#include <cstdlib>
#include <vector>
#include <random>
#include <algorithm>
#include <chrono>
using namespace std::chrono;
static int dummy[2];
int main(int argc, char* argv[])
{
// parsing command line
bool sort = false;
if (argc > 1 && strcmp(argv[1], "1") == 0) {
sort = true;
}
// prepare test data (uniformly distributed random values)
const int arraySize = 5000;
std::vector<int> data;
data.resize(arraySize);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 256);
for (int i = 0; i < arraySize; i++) {
data[i] = dis(gen);
}
// sort or not
if (sort) {
std::sort(data.begin(), data.end());
}
auto start = system_clock::now();
unsigned int count[2];
const int testN = 100000;
for (int t = 0; t < testN; ++t) {
// main loop
memset(count, 0, sizeof(count));
for (int i = 0; i < arraySize; ++i) {
if (data[i] < 128) {
dummy[0] *= dummy[1]; // consume-a-few-cycles
count[0]++; // counting
} else {
dummy[1] *= dummy[0]; // consume-a-few-cycles
count[1]++; // counting
}
}
}
auto duration = duration_cast<microseconds>(system_clock::now() - start);
fprintf(stdout, "sort = %d\n", sort ? true : false);
fprintf(stdout, "total = %d\n", arraySize);
fprintf(stdout, "count = [%u,%u]\n", count[0], count[1]);
fprintf(stdout, "duration = %.2fms\n", duration.count()/1000.0);
return 0;
}
说明
整个测试程序的流程大致分为如下几步:
- 准备一个指定长度(这里用的5000)的
vector<int>,将其填充为一系列指定范围(这里用的0-256)内均匀分布的随机数。 - 根据命令行参数,决定是否对此vector中的数据进行排序。
- 循环测试若干次,记录总的运行时间。其中的每一次测试:
- 循环迭代此vector,使用if语句来判断当前元素的值是否小于指定范围的中间值(此处为128),并在if语句的两个分支中进行统计计数。
- 因为对count变量的自增操作太简单了(太快了),额外增加了一个相对重度的无用语句来消耗CPU时间。
- 打印结果。
其中的关键是3.1中的if语句,CPU将会在这里执行分支预测和推测执行3。当预测失败时,相关的指令会被废除掉(其执行效果不会暴露到Architectural state的层面),并跳转到正确的分支来重新执行。这也就是所谓的misprediction penalty。
大多数CPU厂商没有公开其分支预测器的实现方式4。但从逻辑上说,分支预测器是一个相对简单的硬件电路,它只能基于其设计逻辑或者有限的历史数据来识别某个分支语句的模式,进而作出预测。当某个分支语句被taken的模式越简单,分支预测器的准确率就越高,反之亦然。
就我们的测试程序而言,当vector中的数据是(整体上)均匀分布的随机数时,if语句在下一次执行时哪一个分支会被taken,具有非常大的不确定性,换句话说就是模式很混乱。而当vector中数据进行排序之后,此if语句大致上会在前2500次执行时选择if分支,后2500次执行时选择else分支,预测正确的难度低非常多。
结果
On my MacBook Pro (16-inch, 2019):
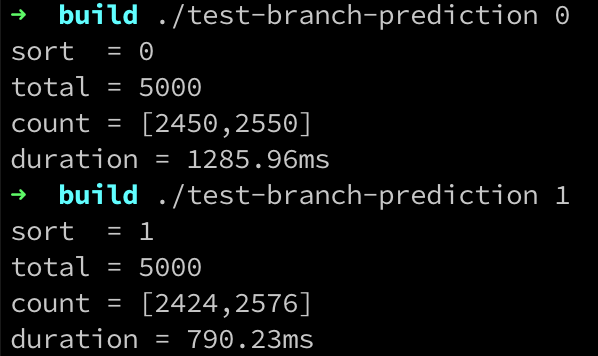
可以看出,排序与否(进而影响分支预测准确率)对于性能的影响还是相当明显的。