CPU缓存伪共享(False Sharing)问题
起因
一个通过蒙特卡洛方法估算 π 值的测试程序,采用了多线程的方式,其代码大致如下:
#include "..."
class RandomNumber
{
mt19937 mt19937_; // random number generator
const float MT19937_FLOAT_MULTI = 2.3283064365386962890625e-10f; // (2^32-1)^-1
public:
void seed(unsigned int seed)
{
mt19937_.seed(seed);
}
float operator() ()
{
return mt19937_() * MT19937_FLOAT_MULTI;
}
};
void worker(int worker_id, int64_t samples, RandomNumber *rnd, int64_t *in)
{
rnd->seed(worker_id); // seed the prng
for (int64_t i = 0; i < samples; i++)
{
float x = (*rnd)();
float y = (*rnd)();
if (x*x + y*y <= 1)
{
(*in)++;
}
}
}
int main(int argc, char* argv[])
{
int num_threads = 16;
int64_t num_samples = 1000000000;
// parsing command line arguments
auto start = system_clock::now();
RandomNumber* rnd = new RandomNumber[num_threads];
int64_t* in_points = new int64_t[num_threads];
int64_t total_points = num_samples;
int64_t circle_points = 0;
vector<thread> threads;
for (int i = 0; i < num_threads; i++)
{
int64_t samples = num_samples / num_threads;
if (i == num_threads - 1)
{
samples += num_samples - samples * num_threads;
}
threads.emplace_back(worker, i, samples, &(rnd[i]), &(in_points[i]));
}
for (int i = 0; i < num_threads; i++)
{
threads[i].join();
circle_points += in_points[i];
}
double pi = 4 * circle_points / (double)total_points;
double pi_true = acos(-1.0); // true value of pi
double error = abs(pi - pi_true) / pi_true * 100;
auto duration = duration_cast<microseconds>(system_clock::now() - start);
fprintf(stdout, "threads = %d\n", num_threads);
fprintf(stdout, "samples = %lld\n", (long long)num_samples);
fprintf(stdout, "duration = %.2fms\n", duration.count()/1000.0);
fprintf(stdout, "pi = %f (%f%% error)\n", pi, error);
fprintf(stdout, "\n");
delete []rnd;
delete []in_points;
return 0;
}
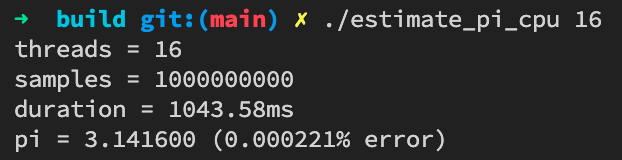
在我的MacBook Pro(16-inch, 2019)上测试,结果为:
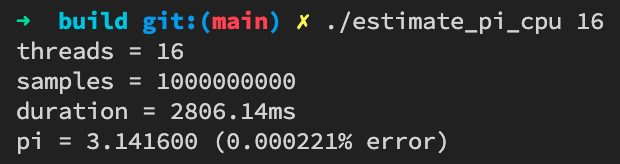
上工具看看这个结果怎么样。祭出Instruments,发现了一个奇怪的问题:
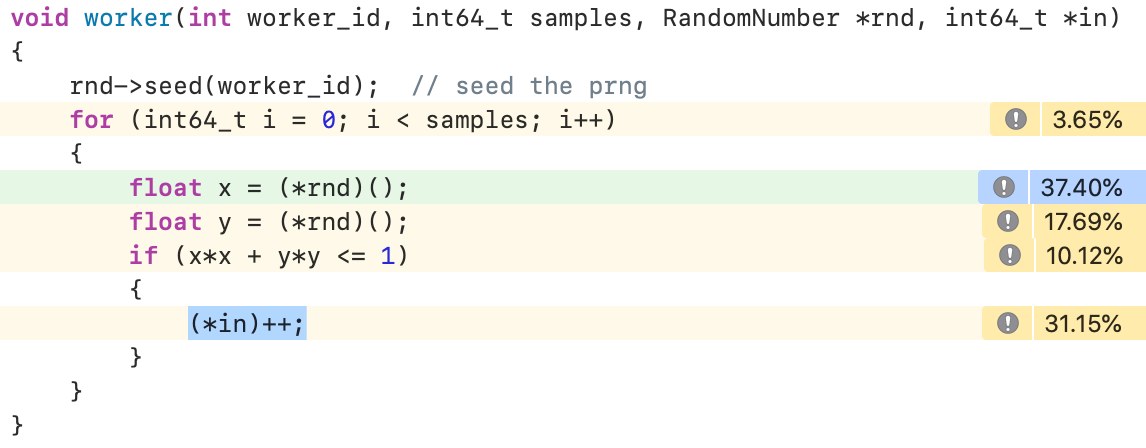
(*in)++这一句对应到Load-Increment-Store三个动作,理论上应该很简单,占用这么多CPU时间不正常。
修复
内存修改性操作 + 多线程,盲猜这是一个 “Cache False Sharing” 问题。对于x86 CPU,Cache Line大小一般为64字节。尝试修复一下:

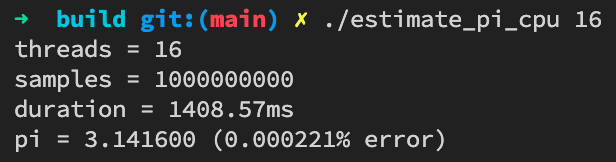
哇,快了1倍左右,效果很明显。现在对counter的自增操作的CPU开销明显低于调用随机数生成器的开销,比较合理。可以确认之前的问题的确是因为存在False Sharing。
虽然问题修复了,不过还是系统回顾一下相关的知识点。
为什么要有Cache?
因为现代计算机存在着显著的 Processor-Memory Speed Gap :
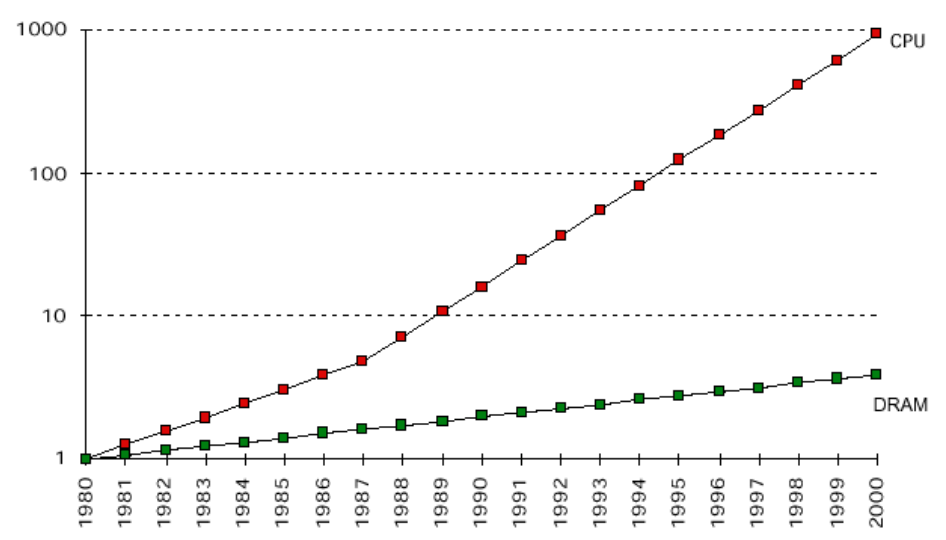 虽然这张图只画到2000年,但这个趋势到目前为止大体上是维持的。
虽然这张图只画到2000年,但这个趋势到目前为止大体上是维持的。
为什么会这样?根据这篇论文1的研究,大致可以归纳为:
the prime reason is the division of the semiconductor industry into microprocessor and memory fields. As a consequence their technology headed in different directions: the first one has increased in speed, while the latter has increased in capacity.
到了1990年代中期,上述问题已经比较明显的影响到了程序运行速度的提升。CPU厂商逐步引入一种被称为Cache Memory的部件,放置于CPU和Memory的访问路径之间,来降低Memory的访问延迟。Cache Memory通常使用SRAM来实现,相比于Main Memory的DRAM,其速度快得多但成本也高得多。
随着架构的演进,当今CPU中通常存在着多级Cache,例如L3-L2-L1,而L1通常还可细分为I-Cache和D-Cache,分别对应着指令流和数据流的加速。
为什么Cache可以降低访问延迟?
计算机程序的访存操作,通常具有时间局部性的特点:
Temporal locality: Recently referenced items are likely to be referenced in the near future.
通过将最近访问到的元素存入Cache,后继操作直接从Cache中处理,由于Cache的访问速度比主内存的访问速度要快得多,因而可以降低整体的访问延迟。程序的时间局部性越好,收益越高。
访存操作通常还具有空间局部性的特点:
Spatial locality: Items with nearby addresses tend to be referenced close together in time.
通过将Cache组织为若干个Cache Line,在访问到某个元素时,将其相邻的一整个Cache Line的元素都整体存入Cache,使得后继对相邻元素的访问可以直接从Cache中处理,进而可以降低整体的访问延迟。程序的空间局部性越好,收益越高。Cache Line的尺寸和CPU架构相关,在x86平台上通常为64字节。
Writing policies
Cache位于CPU和Memory的访问路径之间。对于读操作,其工作逻辑应该很容易理解:CPU读某个内存地址时,若其在Cache中找到,则直接从Cache中返回数据(对应一个Cache Hit);若没有找到,则从Memory中读取对应数据(以Cache Line大小为单位,对齐到Cache Line边界),写入Cache(若Cache中对应存储区域已满,则基于某种策略淘汰一个Cache Line来腾出空间),再返回给CPU(对应一个Cache Miss)。
写操作则要复杂一些。我们先看下常规Cache系统中的一些设计策略2。
- 若待写入的数据在Cache中不存在,是否需要在写入Backing store的同时,将对应内容也存入Cache呢?
- Write allocate: data at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read misses.
- No-write allocate: data at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, data is loaded into the cache on read misses only.
- 每次写入是否都要写入到Backing store,换句话说,是否允许做延迟写(Lazy write)?
- Write-through: write is done synchronously both to the cache and to the backing store.
- Write-back: initially, writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block.
常见的策略组合为:
- A write-through cache with no-write allocation:

- A write-back cache with write allocation:

回想一下,CPU Cache的主要目标是降低Memory的读写延迟,而Write-back with write-allocation在这个目标上明显更有效。因此,多数CPU Cache都采用了这种策略。
Memory Hierarchy
看一下2012年左右的Intel Sandy Bridge E class servers的存储器分层结构3:
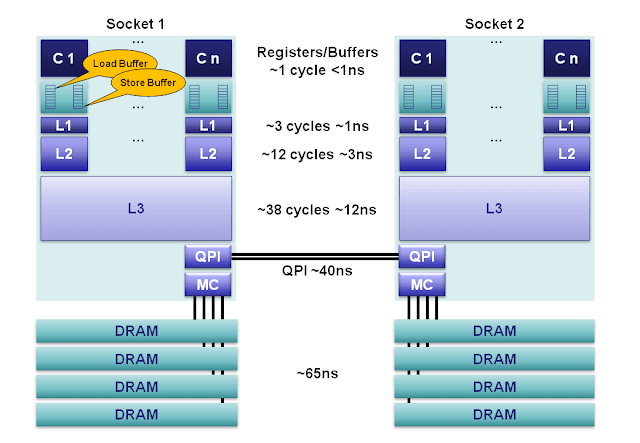
可以看到,最上层为寄存器,速度最快;往下依次为L1, L2, L3, DRAM,其速度逐渐变慢而容量逐渐增大。L1和DRAM的访问速度有几十倍以上的差距。
不过这里有一个问题:L1~L3应该都是基于SRAM来实现,为啥速度不同呢?找到一个回答4说的比较清楚:
Although they use SRAM, they do not all use the same SRAM design. SRAM for L2 and L3 are optimized for size (to increase the capacity given limited manufacturable chip size or reduce the cost of a given capacity) while SRAM for L1 is more likely to be optimized for speed.
Cache Coherence
上图显示的是通过QPI总线相连的两个CPU Socket,各自有其对应的DRAM。不过我们目前先聚焦到单个CPU上。
对于多核CPU,一般是最后一级Cache由整个CPU共享(例如上图中的L3),其之上的Cache(例如上图中的L1, L2)则是每个Core均有一份。这就带来了一个问题:若多个Core都访问(读/写)了同一个内存地址,这个地址的内容会被存入多个Core各自的Cache中;此时若某个Core对此内存地址执行写入操作,如何确保其它Core能感知到此修改,进而能读到此内存地址的最新值?
为了处理上述问题,CPU厂商引入了Cache Coherence Protocol,其中一种最常见的是MESI协议5 (also known as the Illinois protocol),实际你电脑中CPU上跑的协议可能不同但基础原理与之类似。
MESI Protocol
前面已经讲过Cache存取的最小单位是Cache Line。
MESI协议为每个Cache Line定义了四种状态:
- Modified (M)
- The cache line is present only in the current cache, and is dirty - it has been modified from the value in main memory. The cache is required to write the data back to main memory at some time in the future, before permitting any other read of the (no longer valid) main memory state. The write-back changes the line to the Shared state(S).
- Exclusive (E)
- The cache line is present only in the current cache, but is clean - it matches main memory. It may be changed to the Shared state at any time, in response to a read request. Alternatively, it may be changed to the Modified state when writing to it.
- Shared (S)
- Indicates that this cache line may be stored in other caches of the machine and is clean - it matches the main memory. The line may be discarded (changed to the Invalid state) at any time.
- Invalid (I)
- Indicates that this cache line is invalid (unused).
上述四种状态组成一个有限状态机(FSM),某个Core的Cache通过与Bus及其它Core的Cache的协作,在上述状态中进行迁移。相关的内容较多,这里仅举一个例子:
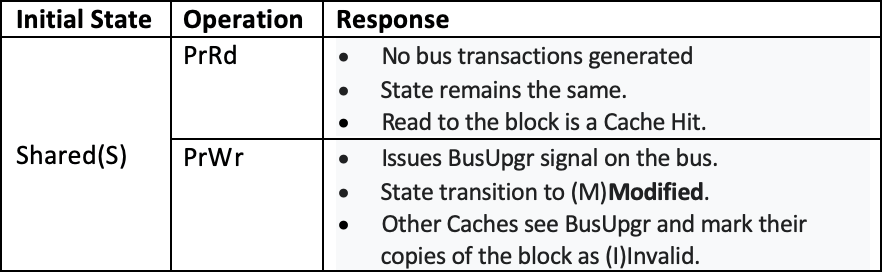 当初始状态为S:
当初始状态为S:
- 当前处理器执行读操作:不产生总线操作;状态继续为S不变;得到一个Cache Hit;
- 当前处理器执行写操作:在总线上产生一个BusUpgr信号;状态迁移至M;其它Core的Cache收到BusUpgr信号时将其对应Cache Line的状态修改为(I)Invalid;
什么是Cache False Sharing?
当多个Core同时读写同一个内存地址时,由于上述的Cache Coherence机制,会产生额外的性能开销。这种情况是真正的“共享”,需要通过修改程序逻辑的方法来优化。
当多个Core同时读写多个不同的地址,但这些地址由于相邻会被映射到同一个Cache Line时,虽然从程序逻辑上不存在内存地址“共享”,但因为Cache实现机制的问题存在一个隐式的“共享”,我们称之为False Sharing。下图6是一个例子:
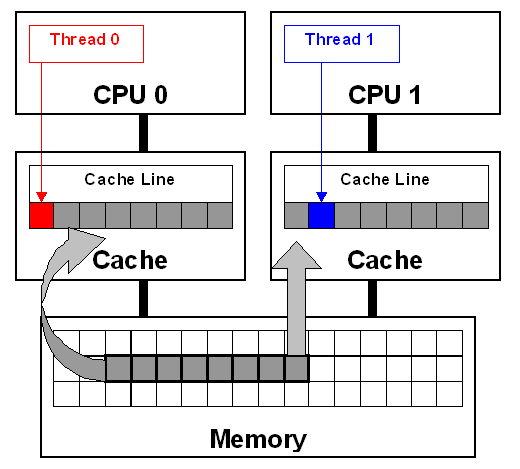
回忆一下之前的示例程序,刚好就是这种情况:多个线程(从多个Core上)持续对位于同一Cache Line的不同变量进行自增操作,其Cache Line会持续的经历S->M的状态迁移,伴随着对其它Core的Invalid操作。这种密集的相互“踩踏”的行为,极大的降低了Cache的命中率,进而大幅度影响到程序的运行效率。
Cache False Sharing在实际工程实践中出现的较为隐蔽,一般需要通过类似VTune7/Instruments/perf这样的profiling工具,结合经验来分析定位。
多想一秒
前面我们通过将counter padding到Cache Line Size,将示例程序的性能提高了一倍,看起来挺不错。不过转念一想,每个线程的counter的中间值并不需要对外暴露,那我们可以将线程的counter存在局部变量(简单类型可以优化为寄存器读写)中,线程执行完时再写回到Memory:
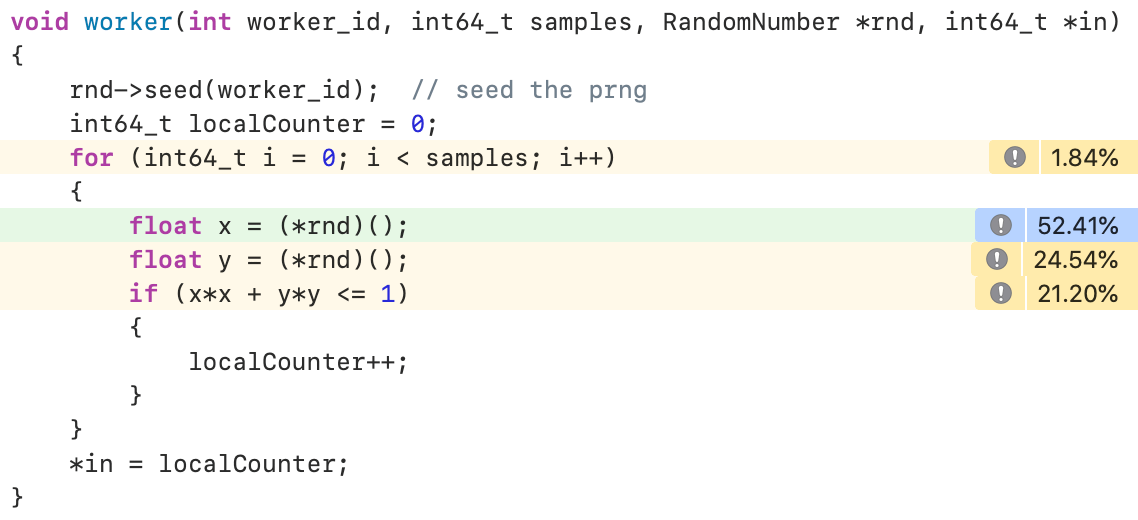
看看效果吧(果然还是寄存器最快!):
References
-
http://gec.di.uminho.pt/discip/minf/ac0102/1000gap_proc-mem_speed.pdf ↩︎
-
https://en.wikipedia.org/wiki/Cache_(computing)#Operation ↩︎
-
https://mechanical-sympathy.blogspot.com/2013/02/cpu-cache-flushing-fallacy.html ↩︎
-
https://superuser.com/questions/724504/processors-cache-l1-l2-and-l3-are-all-made-of-sram ↩︎
-
https://software.intel.com/content/www/us/en/develop/articles/avoiding-and-identifying-false-sharing-among-threads.html ↩︎
-
https://software.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/tuning-recipes/false-sharing.html ↩︎